この記事は2019年8月23日(金)に発生したAWSの東京リージョンで起きた大規模障害について、2019年9月6日時点で分かったことを私なりにまとめてみました。
AWSについてあまり詳しくない人に、ざっくりと理解してもらえるような内容です。
それでは見ていきましょう。
Who(だれ)
AWS (Amazon Web Service)
AWS…アマゾンが提供する事業。サーバなどのコンピュータを自分で用意しなくても、AWSを使えば、定額制や従量課金制で利用できる。
When(いつ)
2019年8月23日(金) 午後0時36分ごろ
Where(どこ)
AWSの東京リージョンの ID「apne1-az4」のAZ(アベイラビリティゾーン)
AZ(アベイラビリティゾーン)…データセンターのこと。データセンターとは、サーバが大量に設置された場所のことです。東京リージョンには4つのAZがあり、その1つで問題が発生しました。
リージョン…AZのある地域のこと。AWS公式(2019年9月時点)によると、世界22か国にリージョンがあり、日本には東京と大阪にリージョンがあります。
ID…複数ある中で識別するための番号のこと
つまり、AWSの東京地域の4つのデータセンターのうちの1つで、問題が発生したということです。
What(なにが)
AZの空調設備
データセンターでは大量のコンピューターが稼働しているため、とても暑くなります。そのためオーバーヒートしない様に空調を適切に管理する必要があります。
How(どのように)
AWSの空調制御は、複数のコントローラ(制御するコンピュータ)により分散管理されていたようです。コントローラ同士で通信を行う事により、全体の空調を管理していたのですが、そのコントローラの1つを切り離そうとしたところ、ソフトフェアの不具合によりコントローラが停止しました。
緊急時の強制排熱を行う操作や、緊急時に自動で空調をフル稼働させるフェールセーフ機能も動作しませんでした。
アマゾンによると、1つのコントローラを切り離す際に、状態が変化したことにより問い合わせや返答の通信が多数発生したことで処理ができなくなり、空調制御システムがダウンしたとのことです。
つまり、部屋のエアコンが効かないのと同じ状況になったということです。
Why(なぜ)
空調制御システムが動作しないことで、データセンターの温度が調整できず、結果として東京リージョンのAZの1つが停止してしまいました。
通常、企業などがAWSでシステムを構築する場合、複数のAZにまたがって構築します。そうすることで、片方のAZがダメになってしまっても、もう片方のAZで運用できるからです。(このことを冗長構成、アマゾンではマルチAZと言います)
ですが、今回の障害によってマルチAZ構成を行っているにも関わらず、多数の企業がサービスを継続できない状況になりました。
有名な所では、スシロー、GU、東急ハンズ、Hulu、Paypayなどのサービスです。
今回、問題となった apne1-az4 というAZでは、以下のサービスを提供するサーバがあったと考えられます。
・ Amazon EC2… サーバリソース(CPUとメモリ)のことです。EC2を使うことで、自分でコンピュータを用意する必要がなくなります。
・Amazon EBS…EC2に使うハードディスク(記憶装置)のことです。EC2には大きな容量がないため、EBSを使うことで沢山のデータを保存できるようになります。
・Amazon RDS … リレーショナルデータベースです。自分でデータベースを用意しなくても、アマゾンが用意をしてくれます。
・ Amazon ALB…ロードバランサ―です。2つのEC2サーバを使って負荷分散をする場合、ALBを使うことで、ALBが通信の受け取りを行い、2つのEC2サーバに割り振ってデータを送ってくれます。
・Amazon ElastiCache…インメモリデータベースです。ハードディスクなどを利用せず、メモリ上でデータベースを展開するため、やり取りがより高速になります。
・Amazon Redshift… データウエアハウスです。データ分析を行う時に、データベースにある無数のデータから、自身の目的に沿ってデータの抽出を行い分析をします。
・Amazon Workspaces…仮想デスクトップです。アマゾンでPCリソースをレンタルし、そのPCリソースを自身の別のPCの画面上で操作することができます。
EC2とEBSがサーバを構成する要素の基礎ですから、上記にあるサービスはEC2やEBSが影響を受けたことにより機能しなくなりました。
ざっくり言うと、上記のサービスもEC2とEBSを使って動いていたため、その2つが停止したことによりサービスが提供できなくなったということです。
その中でも、マルチAZで負荷分散を行うことのできるALB(Application Load Balancer)を設定していた企業でも影響がありました。
これは、利用していたALB自体が、 apne1-az4 のAZで展開されている場合、ALB自体が動作していないため、負荷分散する2つのEC2サーバが正常に動作していても、ロードバランサ-であるALBで処理できないためです。
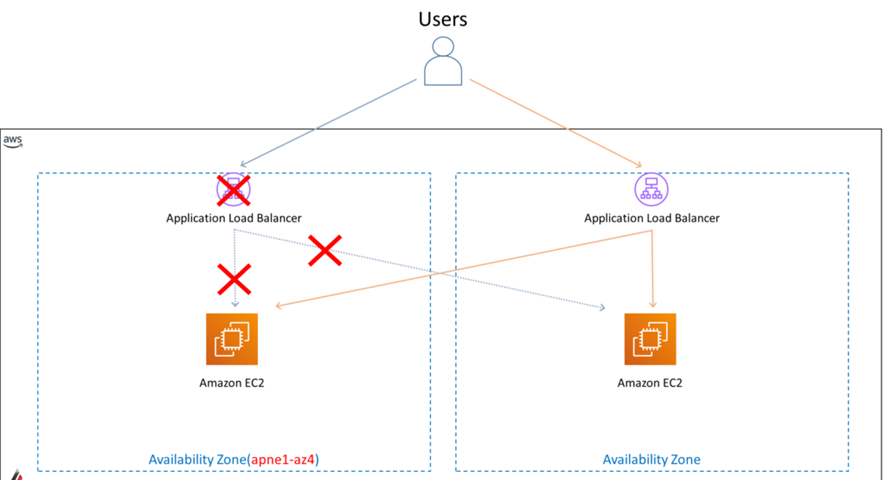
サービスによっては、マルチAZ構成にしていたことにより、被害を免れたり、早急に復旧できたようですが、対応が遅れたサービスは翌日午前中まで停止していたものもあるようです。
まとめ
日本でのAWSの障害により、今後はクラウドの運用方法についてより議論がされそうです。当然の様に、複数のリージョンやAZに配置することでコストが高くなります。
またAWSだけでなく、microsoft Azureや他のクラウドサービスを併用することも考えられますが、運用方法が複雑になりコストも高くなります。費用対効果も併せて考えねばならず、簡単に結論が出るものではありません。
また、日ごろから適切に監視、緊急時対策を行っていることで、障害は防げませんが早期復旧ができる可能性があります。
ますますオンプレミス(自社環境)からクラウドへ移行している昨今ですが、設計から運用方法まで含めて考えることがより求められそうです。
もしこの記事がお役に立ったようでしたら、ブックマークやシェアをしていただけると嬉しいです。
今後もざっくりと分かりやすい記事を投稿いたしますので、また次を楽しみにしていてください。



