Javaを学習しているときに、String型とchar型という2つの型が出てきます。
char型を見た時に、String型でも文字は表現できるのになぜchar型が存在するのだろうか・・・と思った方はいませんか?
実は、String型とchar型は似ているようで全く別物なんです。
今回の記事では、String型とchar型の違いについて解説をしていきたいと思います。
String型
String型は、文字列型ともいわれており、その名の通り文字列を格納するための変数です。
文字数に特に制約はなく、自由に値を定義することができます。
型でいうと参照型です。
※変数の型について、よくわからないという方は次の記事を参考にしてください!
ちなみにString型には何も文字を入れなくても定義することが可能です。
例:String str = “”;
char型
char型は文字型とも呼ばれ、文字を格納することができる変数の型です。
1文字だけを変数として定義することができます。
型としては、データ型です。
char型は文字型だという話をしましたが、実はその実態は文字コードと呼ばれる番号で管理されています。
例えば以下のコードを書いて実行してみてください。
public class Main {
public static void main(String[] args){
char c1 = ‘a’;
System.out.println((int)c1);
}
}
aという値を定義したchar型変数c1をint型にキャストして出力しています。
結果としては、「97」が出力されたと思います。
本来であれば、文字から整数に変換をするなんてことはできませんが、 char型では、それが可能となっています。
なぜかというと、コンピュータは文字を文字コードという番号に割り当てて管理しているためです。
例えば、今回の「a」には、「97」という番号が振られているというわけですね。
今度は以下のコードを実行してみてください。
public class Main {
public static void main(String[] args){
char c1 = 97;
System.out.println(c1);
}
}
char型に整数を定義したら「a」という文字が返ってきましたね。
97という数を指定することで、それを文字コードだと認識して、文字として定義しているというわけです。
文字コードとは?
先ほど、コンピュータにおいて、文字に番号が振られているという話をしました。
この番号のことを文字コードと呼び、文字コードには様々な種類が存在します。
代表的な文字コードはASCIIというコードで、英数字のみを定義した文字コードです。
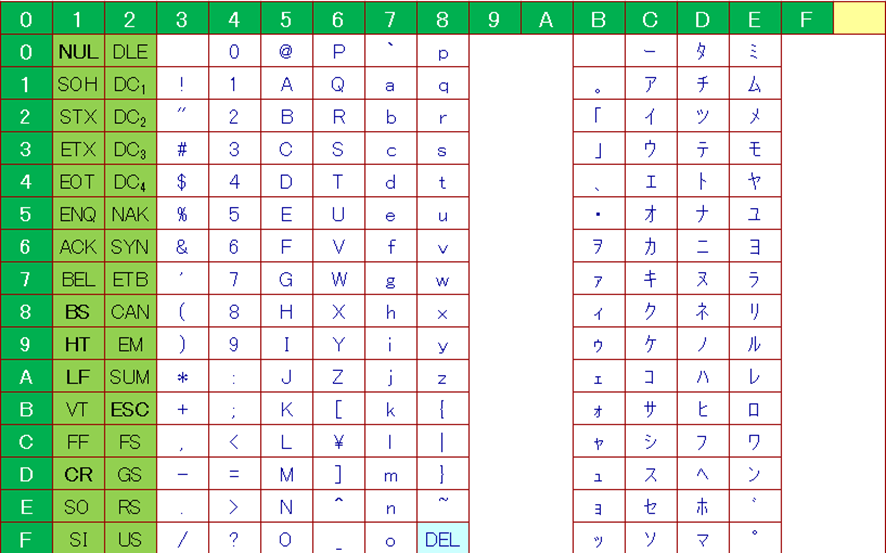
このコードは、英語のみの環境では、とても汎用的に利用されています。
しかし、Javaでは日本語の文字も認識が可能ですよね?
JavaではASCIIコードではなく、Unicodeと呼ばれる文字コードを利用しています。
このUnicodeは、各国の言語による文字コードの差異をなくそうという考えで作られた文字コードで、英語から始まり、日本語はもちろんアラビア語まで利用可能となっています。
さすがにすべての国のコードがあるとなると膨大な量になってしまうのでここではコード表は載せませんが、調べるとすぐに出てくるので、ぜひ調べてみてください。
ちなみに、異なる文字コードでテキストなどを閲覧すると、いわゆる文字化けが発生してしまいます。
例えば、これはこのブログをShift-JISという文字コードとして認識してみた画像です。
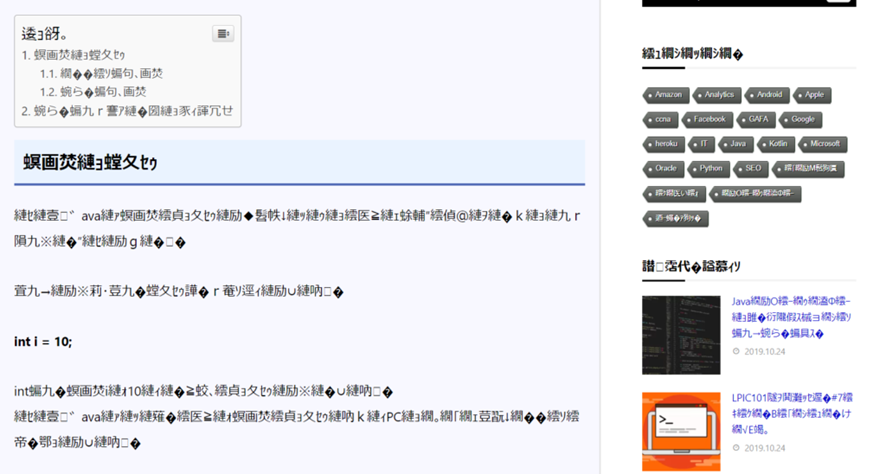
本来であれば、UnicodeでエンコードされるべきものをShift-JISなどの異なった文字コードでエンコードしてしまうと、割り当てられている番号が異なるため、このように文字化けを起こしてしまいます。
逆に言うなら、文字化けを起こしてしまっているサイトを見つけたら、試しに別の文字コードでエンコードすることで、正しい形式で表示させることもできるかもしれませんね。
このように、String型とchar型は似ているようで中身は全く別の方法によって管理されています。
そのため、char型で利用できるメソッドがString型で利用できないこともありますし、その逆もあります。
Javaでは、型ごとに用途が決まっているので、その時その時にあった型を選ぶようにしましょう。



